Les arbres de décisions et les réseaux de neurones semblent être les deux alternatives les plus sexy de ce siècle quand il s'agit de s'attaquer à un problème de classification ou à un problème de régression.
D'ailleurs quand vous devez résoudre ce type de problème,
,car c'est l'un des modèles parmi les plus
Robustes, rapides et facile à prendre en main.
Même pour un noob du machine learning ! C'est d'ailleurs ces dernières propriétés qui justifient entièrement sa popularité au sein de la communauté du Machine Learning.
Il y a plusieurs raisons à cela :
En effet avec juste le nombre d'arbres de décisions qui compose à gérer, et la profondeur maximale de chaque arbre cela en fait l'un de modèle de machine learning avec le moins d'hyperparamètres.
De plus, ces derniers ne sont pas les plus compliqués.
Il n'y a qu'à voir ceux d'une SVM pour en être convaincu. Ces dernières sont bien plus ambiguës et ne font pas référence à des notions humainement simples à comprendre.
Loin de moi de vouloir vous vendre le Random Forest comme l'on vous vendrait une voiture ou une ordinateur portable.
Mais de manière générale, le RandomForest est loin d'être le dernier de la classe quand il s'agit de faire des prédictions. Les résultats obtenus avec ce dernier sont généralement bons, qu'il s'agisse de problèmes de classification ou de régression comme je l'ai dit plus haut.
Bien que de meilleurs modèles permettent de pousser encore plus loin le taux de bonne classification (accuracy en anglais) ou de réduire l'erreur moyenne quadratique (mean square error en anglais) en cas de régression existe, le Random Forest reste véritablement un très bon choix pour commencer le Machine Learning.
Pour finir, comparativement à d'autres modèles, le Random Forest n'est pas l'un des modèles des plus gourmands en données d'apprentissage.
En clair si je devais résumer le Random Forest, je pourrais même dire :
it will give you a good prediction.
Cette phrase résume plus ou moins bien ce que je pense sur Random Forest à ceci dit qu'il faudrait rajouter un warning disant de ne pas mettre de mauvaises données en entrée ou encore même si vous mettez une tonne de données assurez vous qu'il y ait parmi celles-ci des données belles et bien représentatives de votre problème.
En effet, même si le Random Forest est un excellent algorithme de classification, il faut rester réaliste et ne pas s'attendre à des miracles non plus!
Si les données d'entrées ne sont pas bonnes, aucun modèle aussi sophistiqué qu'il soit ne pourra résoudre le problème qui lui est soumis.
Dans cet article, nous verrons successivement :
Ce qu'est un arbre de décision ( C'est ce dont est composé un Random Forest)
Comment ce dernier est entraîné (car oui, pour entraîner le Random Forest, il est d'abord nécessaire de savoir entraîner un arbre de décision)
Ce qu'est le Random Forest et comment il fonctionne
Un petit code Python avec la librairie Scikit-Learn pour mettre en place le Random Forest !


Avant d'étudier plus en détail le Random Forest ou plutôt la "Forêt aléatoire d'arbres décisionnels" (Traduction française du terme Random Forest), il est bien de savoir ce qu'est d'abord un arbre décisionnel !
L'arbre de décision est l'unité de base qui compose le RandomForest.
Il s'agit d'un modèle simple qui tend à résoudre un problème de machine learning en le modélisant comme une suite de décisions en fonction des décisions qui ont été prises ultérieurement.
Prenons un exemple !
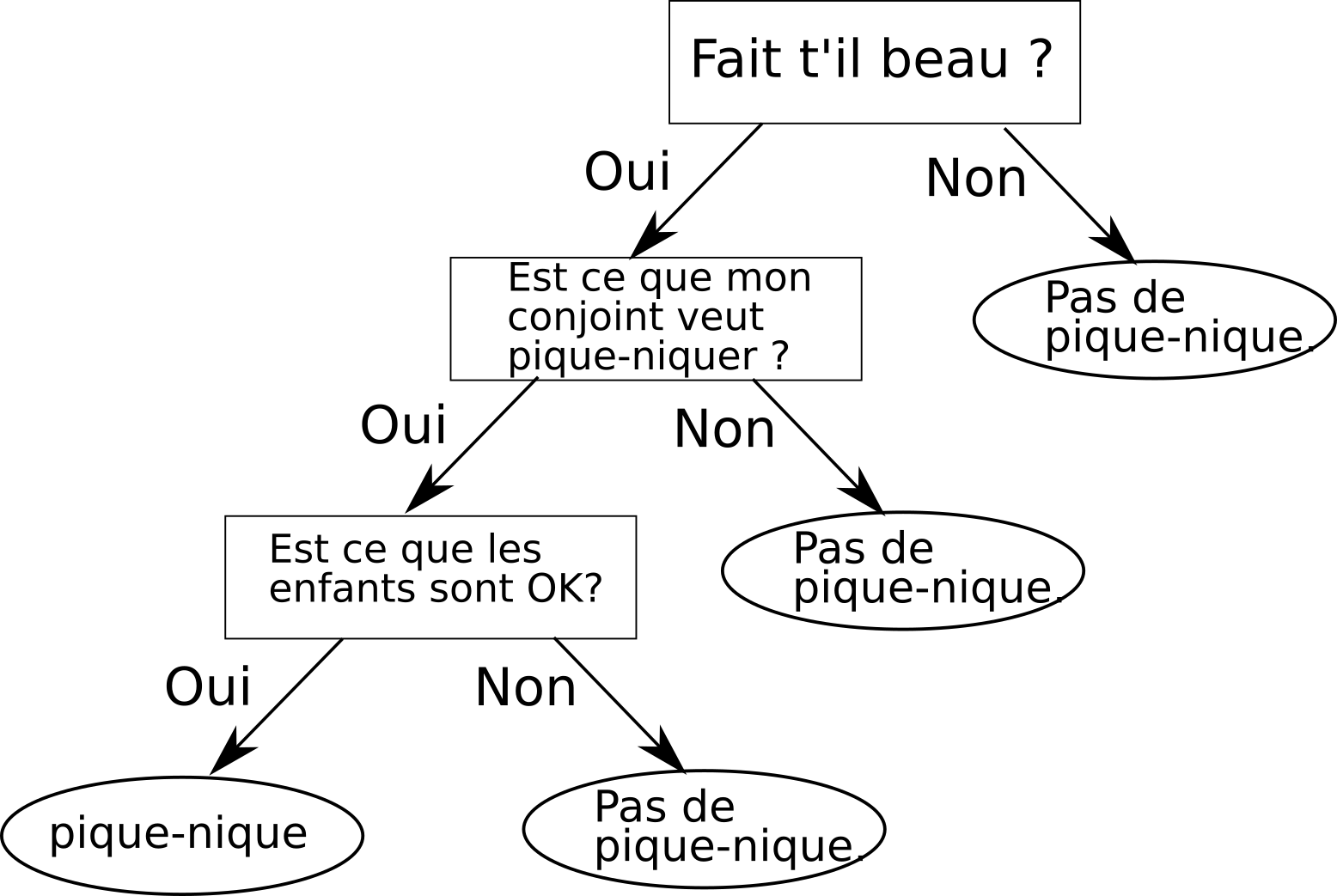
Supposons qu’aujourd’hui, vous vouliez pique-niquer avec votre compagne ou compagnon et vos enfants.
Tout d’abord pour savoir si cela est possible, vous allez d'abord vous assurer qu'il y a du beau temps aujourd'hui, car il serait bête d'aller pique-niquer et que la pluie vous tombe là-dessus.
Si c'est le cas, vous allez alors demander à votre conjoint(e) si elle est intéressée à l'idée de pique-niquer. Si ça ne lui dit pas, on s'arrête la, ça ne sert à rien d'aller demander aux enfants.
Mais sinon, si ça lui dit, ben, vous irez alors demander aux enfants si eux aussi, ils sont également "OK" pour aller pique-niquer aujourd'hui.
Et si c'est le cas, vous et votre famille irez passer une agréable journée dans un parc ou sur une plage.
Le processus de décision que je viens de décrire est une bonne illustration du principe de fonctionnement d'un arbre de décision.
J'ai d'ailleurs réalisé ci-dessous l'arbre de décision correspondant à ce processus.
Maintenant, je suis sûr qu'une question vous brule les lèvres. Et si ce n'est pas le cas ça devrait l'être et oui vous l'aurez peut-être deviné, mais je parle bien sûr du processus de construction ou plutôt d'entrainement d'un arbre de décision.
Exemple d'un arbre de décision pour la classification d'espèce de fleur
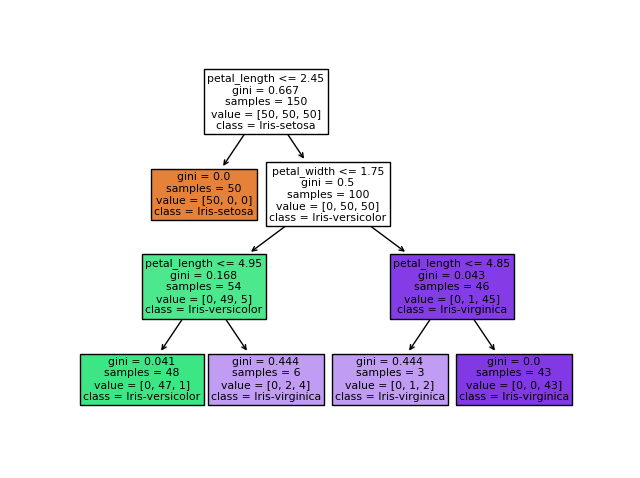
À l'initialisation, l'arbre de décision est vide. Puis l'algorithme d'entrainement va regarder parmi toutes les décisions qu'il est possible de prendre, quelle semble être la meilleure décision qui peut servir de racine (première décision) à l'arbre. Dans le cas d'un problème de classification, la racine sera la décision qui sépare au mieux les classes du problème.
Pour ce faire, l'algorithme va devoir étudier toutes les décisions qu'il est possible de prendre et les comparer entre elles.
Une mesure bien astucieuse a été inventée pour cela, il s'agit du
Le score "Gini" est une valeur numérique comprise entre 0 et 1 qui indique quelle est la probabilité que l'arbre se trompe lors de la prise de décision.
À chaque fois qu'il faudra rajouter une branche à l'arbre, ce score sera calculé afin d'évaluer la pertinence de la décision que l'algorithme souhaite rajouter. La décision qui permet alors à l'arbre de deviner ou de calculer le plus correctement le résultat est sélectionnée et rajoutée à l'arbre.
Voici la formule de calcul du score "Gini"
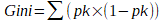
Avec pk étant la probabilité d’obtenir la classe k en cas de rajout de la décision.
Si l'on reprend l'exemple ci-dessus, le score "Gini" vaudra :
P_pique_nique x (1 - P_pique_nique) + P_non_pique_nique x (1 - P_non_pique_nique)
Il est à noter que le score Gini n'est pas toujours utilisé pour entrainer l'arbre. Parfois, l'entropie qui est une mesure du désordre généré par la décision que l'arbre évalue est utilisée à la place de ce dernier.
Dans la section précédente, je vous ai expliqué que pour construire un arbre décisionnel, l’algorithme d’entraînement cherche à maximiser le score Gini à chaque "division" de l'arbre.
Cette méthode est très bonne, mais elle présente un défaut !
L'arbre obtenu n'est pas optimal. Avec cette méthode, rien ne dit que l'on n’aurait pas pu obtenir un bien meilleur arbre si nous n'avions pas varié l'ordre de la prise des décisions.
Car théoriquement, rien ne prouve que l'ordre dans lesquelles les décisions ont été prises est le meilleur parmi tous les ordres qu'il est possible de choisir.
C'est pour résoudre cet inconvénient que le Random Forest a été inventé :
Le Random Forest est comme son nom l’indique et comme je l'ai mentionné plus haut "une forêt aléatoire d’arbres décisionnels".
Il s'agit donc de construire plusieurs arbres de décision, de 2 à l'infinité (selon le souhait de l'utilisateur), et de tous les entraîner, pour finir par prendre la décision que tous ou du moins que la majorité considérera comme la meilleure.
C'est un concept très bien connu en bourse, si vous achetez de nombreuses actions dans un marché haussier, il est plus probable que plus de la moitié des actions monte et donc que votre investissement fructifie, car nous sommes dans le cas d'un marché haussier que si vous aviez acheté une seule action. Dans ce dernier cas, vous n'auriez alors eu qu'une chance sur deux de faire fructifier votre investissement.
C'est également le même principe quand vous révisez en groupe ou travaillez en groupe, il y aura toujours un de vos camarades ou de vos collègues qui sera là pour couvrir le trou (l'erreur peut-être), ou du moins pour apporter un plus à votre travail qui permettra de le valoriser encore mieux. Cela est possible uniquement, car votre collègue a une expérience différente de la vôtre.
A l'image des deux processus que j'ai illustrés précédemment, l'idée derrière le Random Forest est qu'en entraînant plusieurs arbres de décision plutôt qu'un seul, ayant tous une expérience différente le groupe d'arbres de décision sera bien plus à même de prendre une meilleure décision pour résoudre le problème que si ce n'était qu'un seul arbre de décision qui avait été entraîné.
En clair, plus l'on augmente le nombre d'arbres présents dans la forêt d'arbres décisionnels et plus il y a de chance que cette dernière converge vers la solution optimale du problème que l'on cherche à résoudre.
C'est une idée qui a été reprise par de nombreux algorithmes de machine learning tels que Adaboost, logiboost, le logistic model tree (LMT), ou encore les comités de décision.
Maintenant, une question doit probablement vous ronger l'esprit, vous tarauder. Comment est construit le Random Forest et comment prend-il ses décisions.
L'algorithme d'entraînement du Random Forest construit chacun des arbres de décisions qui le composent, en les entraînant tous avec un sous-ensemble des données du problème.
Il choisit aléatoirement des données auxquelles une partie des arbres de décisions n'auront pas accès tandis qu'une autre y aura accès afin de les rendre totalement aveugles à ces dernières et de s'assurer que tous les arbres de décision aient bien une expérience différente du problème.
Une fois l'entraînement de tout les arbres de décision terminés, le Random Forest prend ses décisions relativement au problème de classification ou de régression à résoudre, en faisant voter tous les arbres de décisions qui le compose.
La décision de la majorité l'emporte alors.
#Importation du jeu de données Iris depuis sklearn
from sklearn.datasets import load_iris
#Importation du RandomForest
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# Load data
iris = load_iris()
#Déclaration du RandomForest
randomforest=RandomForestClassifier(n_estimators=30)
#Déclaration des variable d'entrée du jeu de données
X = iris.data
#Déclaration de la réponse voulu
y = iris.target
#Entrainement du RandomForest
randomforest.fit(X, y)
#Calcul de la performance du RandomForest en cross-validation
score = cross_val_score(randomforest, X, y,cv=10)
print ("Sur ce jeu de données, le taux de succès en classification moyen de :",score.mean())
#Calcul de la prédiction du Random Forest pour le jeu de données X
y_predit=randomforest.predict(X)
print (X)